ツゥルヴェイ氏(以下同):現在 Recorded Future 社の CEO を務めている、もうひとりの創設者であるクリストファーが Web の情報を分析する研究を行っていました。その頃私はある調査機関で、過去のデータを元にして、鉄道の電車がいつ故障するかを予測するアルゴリズムの研究をしており、私とクリストファーが専門分野を組み合わせれば、これから発生する事態を予測する事業をはじめられると思ったのです。社名はその思いをこめています。
三つめの、そして最大の特徴は、収集したデータの分析に機械学習を取り入れ、自動化とスピード化を進めているところです。企業でスレットインテリジェンスサービスを選定するときに、自社関連情報をトライアルで分析してもらうことがありますが、パイロットレポートがでるまでには長い場合は数週間かかることもあります。Recorded Future は 80 万のソースの情報を、9年前から現在までリアルタイムで収集分析していますので、社名なり IP アドレスを指定してもらえれば、すぐにトライアルレポートを出すことができます。
――スレットインテリジェンスサービスにおける Google のような情報量・処理量ですね。
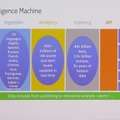
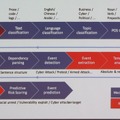
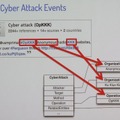
Google はすべての情報をインデックスしようとしていますが、我々は、スレットインテリジェンスに特化した情報をタグづけしています。解析の流れは、まず情報ソースからテキストを抽出し、ログなのかコードなのか、言語はなにか、トピックはなにかをタグ付けします。次に、マルウェアや社名などのキーワードを調べ、どんな文脈で出現しているか、どのようなイベントなのか(攻撃行動か事前調査か)を特定し、最後に日付と時刻の分析を行いリスクスコアを算出します。このシーケンスのほとんどが機械学習で自動化されていますが、イベントの抽出、日付の分析、リスクスコアリングはルールベース(アルゴリズム)で行っています。