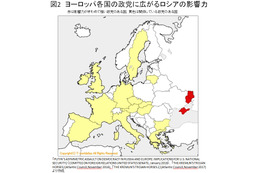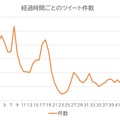
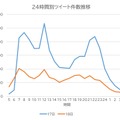
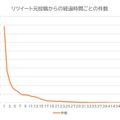
十分な調査も行わず、あおり見出しをつけて、ひたすら部数を伸ばすことに専念する見下げた報道姿勢は昔からあり、かつて「イエロージャーナリズム」と呼びました。あたかも 2020 年代の日本における不倫報道のように、1900 年代のニューヨークでは、新聞同士が部数争いをする過程で、センセーショナルな犯罪報道が主要コンテンツとして扱われ、イエロージャーナリズムが成長しました。
監視資本主義時代、「コードが読める/書けるジャーナリスト」として活躍する作家の一田和樹氏は、SNS を舞台として繰り広げられる世論の誘導や操作を、イエロージャーナリズムの SNS 版「シリコンジャーナリズム」と呼び、警鐘を鳴らしています。かつてメディアを所有し情報発信をすることができる人は限られていました。しかし現代、新聞王に負けず劣らずの発信力を一般市民が手にし、その力を謳歌しています。
今回 Scan PREMIUM 会員に向け、前後編 2 回でお届けするこの特別寄稿では、シリコンジャーナリズムの解説にとどまらず、フリー統計ソフト「R」を用いてツイートの分析を行い、誘導と操作によって歪められたデータの中から事実を見つけ出す具体的方法を伝授する、いわば「シリコンジャーナリズム・ハック・マニュアル」ともなっています。
前編「存在しない『炎上』の作り方」につづく今回の後編では、今春日本で起こったいわゆる「LINE 騒動」を調査テーマとして取り上げ、Twitter の API から取得したデータをフリーの統計ソフトで解析し分析を行います。

● LINE 騒動のデータ
分析のテーマは何を選んでもいいのだが、今春、LINE 騒動が大きな話題になって記憶にある人も多いと思うので、LINE 騒動を題材にして一連の集計をやってみたい。
まず、ツイッター API からデータを取得する。LINE だけの検索だと関係ないものが多数含まれるので、下記の条件にした。条件を決めるに当たってはいくつか類似パターンを試し、もっとも適した検索結果を返すものを選んだ。
LINE AND (中国 OR 韓国 OR 個人情報 OR 問題 OR 自治体 OR 停止 OR 調査 OR 流出 OR 漏洩 OR 公共団体)
これを実際の式にすると下記になる。
Ltweet =search_tweets("LINE (中国 OR 韓国 OR 個人情報 OR 問題 OR 自治体 OR 停止 OR 調査 OR 流出 OR 漏洩 OR 公共団体) since:2021-03-19_00:00:00_JST until:2021-03-19_05:00:00_JST",n=19000,include_rts = TRUE,langs = "ja")
とりあえず 48 時間データをとることとして、データ制限を避けて何度か繰り返してデータ取得を行った。
取得したデータには集計に必要ではないものも含まれていたので、項目を絞って保存した。
lx=Ltweet[,c("user_id", "status_id","created_at", "screen_name", "name", "text", "favorite_count", "retweet_count", "source", "followers_count", "friends_count", "account_created_at", "is_retweet", "retweet_status_id","retweet_text", "retweet_created_at", "retweet_user_id", "retweet_screen_name", "retweet_name", "retweet_description","retweet_followers_count","retweet_friends_count","retweet_statuses_count", "location", "status_url")]
write.csv(lx,,file = "/Users/rdata/LINE/L2_19_00_05.csv",row.names = FALSE)
全てのデータを取得したら保存したデータを全てひとつに合わせて集計を行う。
集計の前にクリーニングを行った。取得したのは 187,907 件だったが、関係ないデータをクリーニングした結果、185,127 件となった。
全データ :185,127件
RT :144,357件(77.98 %)
オリジナル RT:6,339件
監視資本主義時代、「コードが読める/書けるジャーナリスト」として活躍する作家の一田和樹氏は、SNS を舞台として繰り広げられる世論の誘導や操作を、イエロージャーナリズムの SNS 版「シリコンジャーナリズム」と呼び、警鐘を鳴らしています。かつてメディアを所有し情報発信をすることができる人は限られていました。しかし現代、新聞王に負けず劣らずの発信力を一般市民が手にし、その力を謳歌しています。
今回 Scan PREMIUM 会員に向け、前後編 2 回でお届けするこの特別寄稿では、シリコンジャーナリズムの解説にとどまらず、フリー統計ソフト「R」を用いてツイートの分析を行い、誘導と操作によって歪められたデータの中から事実を見つけ出す具体的方法を伝授する、いわば「シリコンジャーナリズム・ハック・マニュアル」ともなっています。
前編「存在しない『炎上』の作り方」につづく今回の後編では、今春日本で起こったいわゆる「LINE 騒動」を調査テーマとして取り上げ、Twitter の API から取得したデータをフリーの統計ソフトで解析し分析を行います。
● LINE 騒動のデータ
分析のテーマは何を選んでもいいのだが、今春、LINE 騒動が大きな話題になって記憶にある人も多いと思うので、LINE 騒動を題材にして一連の集計をやってみたい。
まず、ツイッター API からデータを取得する。LINE だけの検索だと関係ないものが多数含まれるので、下記の条件にした。条件を決めるに当たってはいくつか類似パターンを試し、もっとも適した検索結果を返すものを選んだ。
LINE AND (中国 OR 韓国 OR 個人情報 OR 問題 OR 自治体 OR 停止 OR 調査 OR 流出 OR 漏洩 OR 公共団体)
これを実際の式にすると下記になる。
Ltweet =search_tweets("LINE (中国 OR 韓国 OR 個人情報 OR 問題 OR 自治体 OR 停止 OR 調査 OR 流出 OR 漏洩 OR 公共団体) since:2021-03-19_00:00:00_JST until:2021-03-19_05:00:00_JST",n=19000,include_rts = TRUE,langs = "ja")
とりあえず 48 時間データをとることとして、データ制限を避けて何度か繰り返してデータ取得を行った。
取得したデータには集計に必要ではないものも含まれていたので、項目を絞って保存した。
lx=Ltweet[,c("user_id", "status_id","created_at", "screen_name", "name", "text", "favorite_count", "retweet_count", "source", "followers_count", "friends_count", "account_created_at", "is_retweet", "retweet_status_id","retweet_text", "retweet_created_at", "retweet_user_id", "retweet_screen_name", "retweet_name", "retweet_description","retweet_followers_count","retweet_friends_count","retweet_statuses_count", "location", "status_url")]
write.csv(lx,,file = "/Users/rdata/LINE/L2_19_00_05.csv",row.names = FALSE)
全てのデータを取得したら保存したデータを全てひとつに合わせて集計を行う。
集計の前にクリーニングを行った。取得したのは 187,907 件だったが、関係ないデータをクリーニングした結果、185,127 件となった。
全データ :185,127件
RT :144,357件(77.98 %)
オリジナル RT:6,339件