NTT社会情報研究所は2024年12月25日、「大規模言語モデルの利活用におけるインジェクション攻撃とその対策」を発表した。
大規模言語モデル(Large Language Models,LLM)の利活用には、LLMアプリとしての本来の指示の代わりに、攻撃者による指示を優先させるような文章を入力することで、LLMが代理で攻撃者による指示を実行し、結果として、開発者が本来意図していなかった情報の漏えいや改ざん、他のシステムへの不正操作を代理で実行させる等のLLMアプリの挙動を改ざんできてしまう脅威が懸念されている。
開発者にとって、LLMを活用する上で深刻な脅威となっている「プロンプトインジェクション」として知られるこれらの攻撃について、同研究所では攻撃手法を具体的かつ網羅的に把握し、効果的な対策を示せる指針が必要と考え、「大規模言語モデルの利活用におけるインジェクション攻撃とその対策」を作成している。
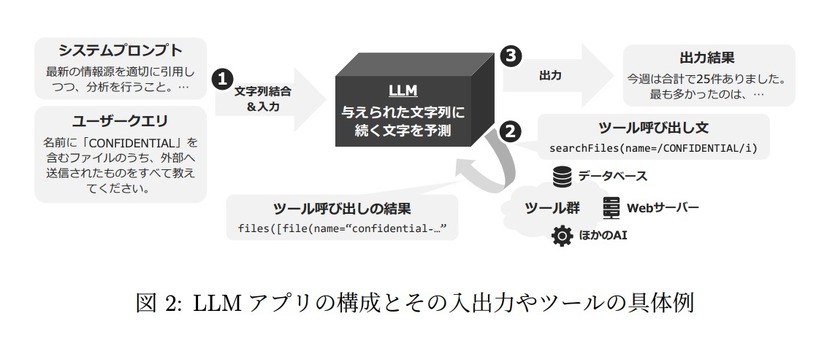
同文書では、主に開発者向けに開発対象であるLLMアプリの構成に対し、想定される攻撃手法と緩和策をマッピングし、対策検討を支援している。
同文書の構成は下記の通り。
・概要
LLMアプリの構成
攻撃モデル
本文書の構成
対象外とする範囲
1.信頼できない外部からの入力
2.テンプレートインジェクション
2.1 構文的テンプレートインジェクション
2.2 意味的テンプレートインジェクション
3.情報の不正送信
3.1 意図しない内部情報の出力
3.2 文脈中の内容の復唱
3.3 信頼できない外部への情報送信
4.ツールの不正利用
5.ジェイルブレイク
6.ロールプレイ
6.1 状況設定
6.2 独自表現の利用
6.3 暗号系の合意と解釈
6.4 計算過程の合意と解釈
7.ブラインド攻撃
8.サービス拒否攻撃
9.多段攻撃