
リスクベース認証に必要な不正検知やふるまい検知にとって、AI(機械学習や統計学的手法)は欠かせない存在だ。AI のセキュリティ応用技術では中国やアメリカ、イスラエルが世界をリードしているが、国内で同様な研究がないわけではない。
DeepProtect は NICT(情報通信研究機構)と神戸大学が共同で開発した技術。しかも技術移転で2022年3月に、民間セキュリティベンダー、株式会社イエラエセキュリティ(現 GMOサイバーセキュリティ byイエラエ株式会社)が実際にサービスとして採用した。
■機械学習にはとにかく大量のデータが必要だが
たとえばカードの不正利用は、短時間での連続高額決済、生活圏ではない海外での決済など、比較的わかりやすい条件で検知できるかもしれない。だが、オレオレ詐欺による本人操作、なりすましや不正アクセスによる活動の検知は、さらに高度なアルゴリズムや機械学習のような力を借りる必要がある。
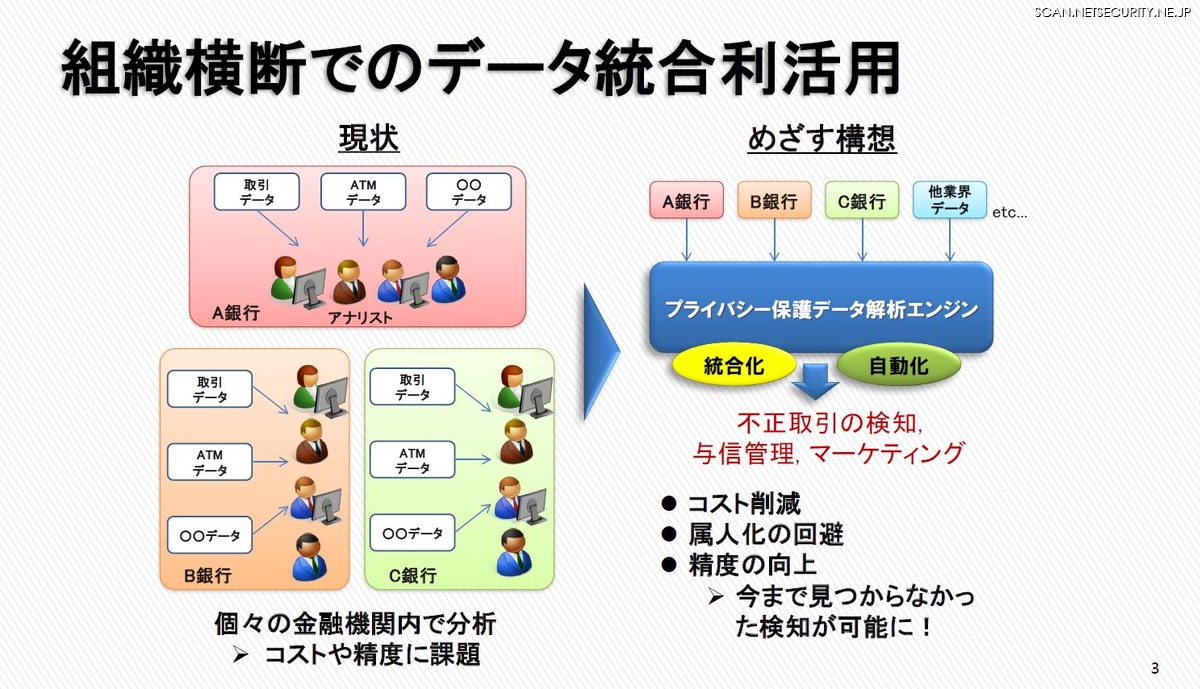
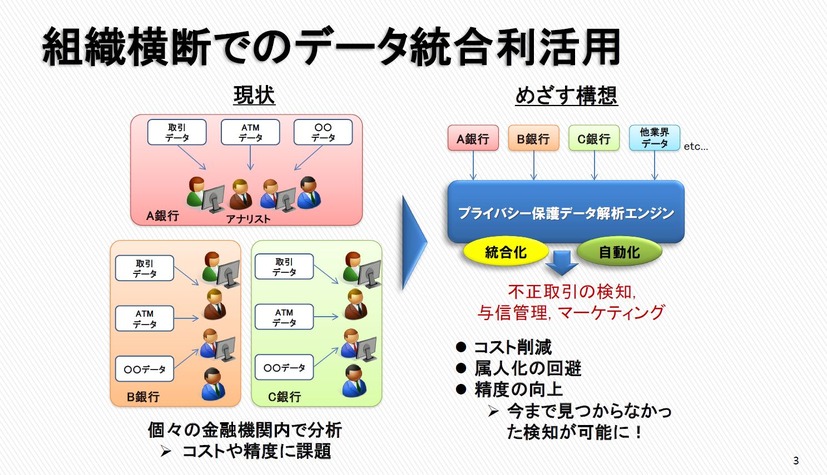
一方で、機械学習の精度を上げるには、一にも二にも学習データの量とバリエーションがものをいう。そのため金融機関やクレジット会社は、より多くの取引データ、ATM データがほしいことになる。だが現実には、同じ銀行でも支店や部署ごとに個別にデータ管理を行っていて連携がうまくいっていない場合もある。金融機関が変われば、そのデータ連携や共有はさらに困難になる。あたりまえだ。
なぜなら金融機関の取引データは重要な個人情報を含んでいる。金銭目的の犯罪者にとっても利用価値が高い。個人情報保護法の観点でも、防犯の観点でも取引データ、ATM データ、顧客データの共有・連携は簡単ではないし、慎重にも慎重な配慮をもって行われるべきだ。
理想的には、さまざまな金融機関の取引データを利用して AI に学習させることができれば、セキュリティ製品、対策ソリューションの不正検知、犯罪検知の精度を上げることができる。だが、現実には、金融機関ごとのデータで AI をチューニングするしかない。
■学習データではなくモデルパラメータを暗号化共有
DeepProtect は、この問題に対応すべく考えられた。
技術的には各社・各金融機関の取引データを集約して全体の学習モデルを構築することは可能だし、個人情報を含む取引データの集約ができないなら、学習モデルのパラメータだけを集めて、中央サーバーで学習モデルをアップデートすればよいのではないか。これが DeepProtect の基本的な考え方だ。
![[まさか本気でそんなに儲かると思った?]サイバー犯罪者さん 職種別給与一覧 ~ 求人広告22万件調査 画像](/imgs/p/2w5IdCqve0mMIzS4K5kC-28IDAerBQQDAgEA/40532.jpg)



